
image credit: https://www.miningglobal.com/smart-mining/six-most-significant-open-pit-mines-world


Figure 05 - a 2D geological setting where samples of effective porosity are taken. Samples are paired along the major direction of continuity and with a specific lag distance. The points that are paired are shown with red flashes (Eidsvik, J. Pyrcz and Deutsch, 2015).
|
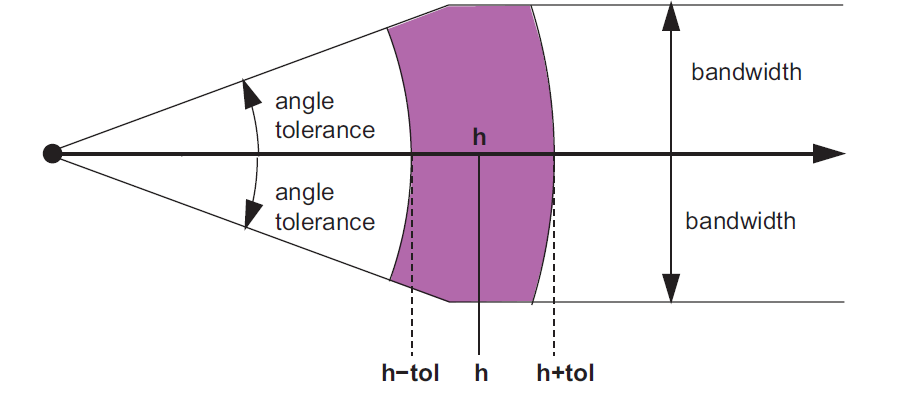
Figure 06 - samples are paired with a degree of tolerance with regards to direction and distance (called angle tolerance and lag tolerance). This allows for more pairs of points to be counted which decreases erratic changes in the variogram. Bandwidths restrict the angle tolerance so that irrelevant points would not be paired together, as distances increase (Eidsvik, J. Pyrcz and Deutsch, 2015).
|






